System Design Requirements
Good system design starts simple and grows intentionally.
Build an MVP (minimum viable product), watch for real bottlenecks, and scale when the signals tell you to—not before.
Use the checklist below to identify which requirements matter for your system—and use the same language when you write your own requirements.
Requirements Checklist
Section titled “Requirements Checklist”These are the dimensions that matter when you design or review a system.
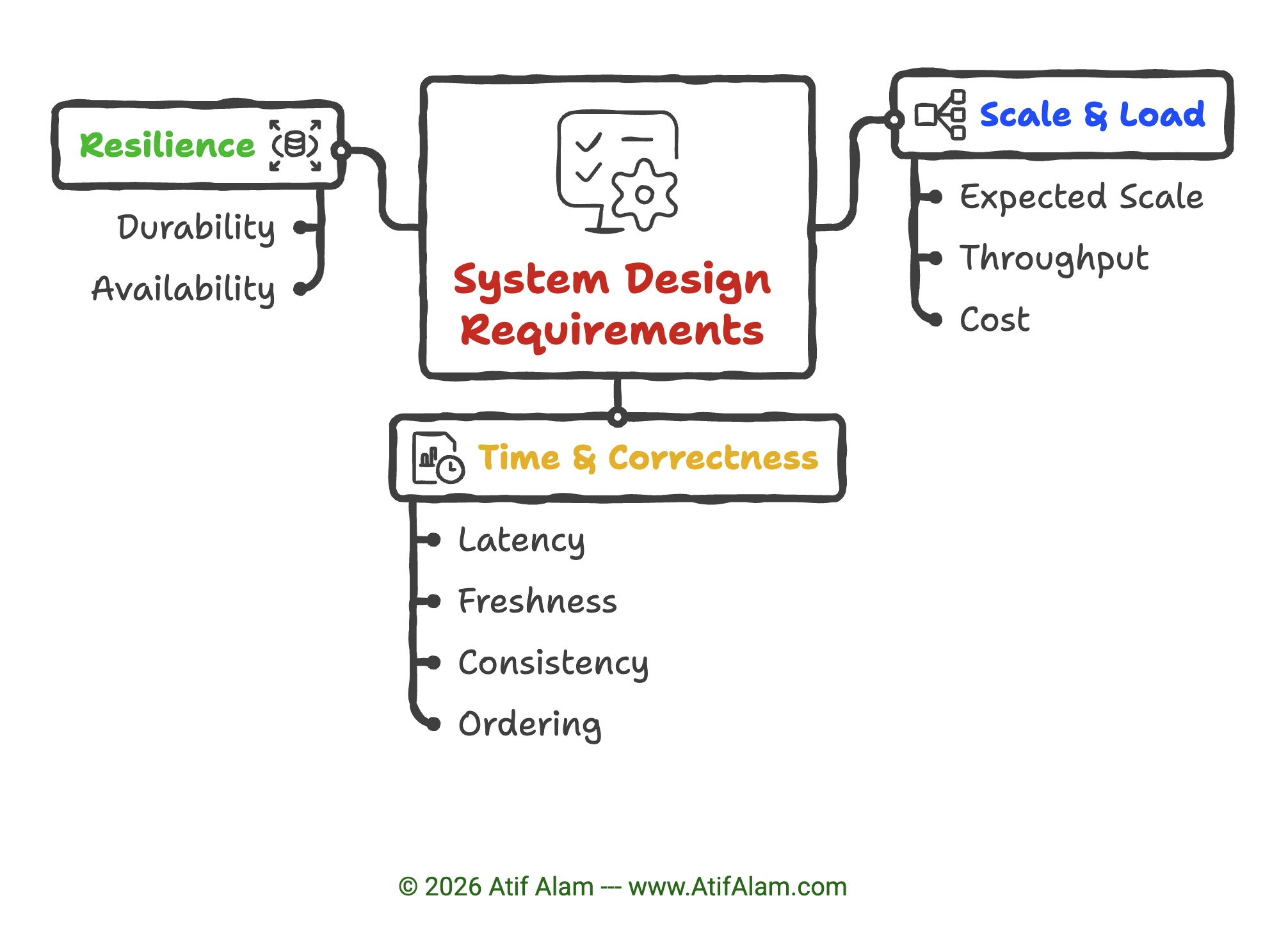
| Dimension | What it means | You care when… |
|---|---|---|
| Scale & Load | ||
| Expected scale | How big does this get? Daily active users (DAU), concurrent connections (CCU), storage growth over time | Almost always—sets your capacity baseline |
| Throughput | How many operations per second? Requests/sec, events/sec, orders/day | High-volume ingest or read paths |
| Cost | What are the cost drivers? Storage, compute, retention windows, and tiering decisions | High-volume ingest, long retention windows |
| Time & Correctness | ||
| Latency | How fast does a request need to come back? Measured as p95/p99 response time | Users wait for a response (API, search, feed) |
| Freshness | How soon does new data need to appear for readers? Seconds, minutes, or hours | Feeds, dashboards, search indexes |
| Consistency | Can readers see stale data, or must every read reflect the latest write? Strong vs eventual, read-your-writes | Multiple writers, ordering matters, financial data |
| Ordering | Does the order of events matter? Per-channel, per-partition, or per-key ordering | Chat, collaborative editing, event streams |
| Resilience | ||
| Durability | Can you afford to lose data? Covers replication, persistence, and delivery guarantees (at-least-once, exactly-once) | Payments, audit trails, event retention |
| Availability | How much uptime do you need? Expressed as a target like 99.9%, with failover expectations | User-facing, revenue-critical |
Requirement → Design Pattern Mapping
Section titled “Requirement → Design Pattern Mapping”The trick is to treat each dimension as a signal that points you toward a component or pattern.
The mappings below are limited examples to spark your imagination—system design is a vast, detailed subject and depends on your exact app requirements. For more details, read the System Design Checklist, Infrastructure Building Blocks, and Optimization Quick Reference.
Expected Scale (DAU / CCU / Storage)
Section titled “Expected Scale (DAU / CCU / Storage)”- Millions of users → assume you need horizontal scaling from day one; stateless services behind a load balancer
- Storage growing fast → plan tiered storage (hot/warm/cold) and think about whether a single DB can handle it
- High CCU → connection pooling, or move to event-driven to avoid thread-per-connection limits
Throughput (ops/sec)
Section titled “Throughput (ops/sec)”- Very high write throughput → stream ingestion (e.g. Kafka) to buffer writes, or write-optimized design: append-only/LSM, batching, partitioning; or a DB built for high write throughput (e.g. Cassandra, ClickHouse)
- Very high read throughput → cache layer (Redis) in front of DB
- Bursty traffic → queue to buffer and smooth the load
Cost (storage, compute, retention)
Section titled “Cost (storage, compute, retention)”- Long retention + high volume → cold storage tiering (S3 Glacier), compaction policies in Kafka, TTLs in cache
- Compute-heavy → evaluate async batch processing over real-time (cheaper per unit)
- Storage-heavy analytics → columnar store (Parquet on S3 + Athena, or ClickHouse) vs row store
Latency (p95/p99)
Section titled “Latency (p95/p99)”- Sub-100ms reads → cache is mandatory; no live DB query on the hot path
- Sub-50ms globally → add a CDN for static assets, consider edge computing
- Slow writes acceptable → offload to async queue, return immediately to user
Freshness (how stale is OK?)
Section titled “Freshness (how stale is OK?)”- Seconds → push model (WebSockets, SSE) or short TTL cache; CDC from DB to downstream
- Minutes → poll-based refresh or stream consumer updating a read store
- Hours → batch jobs are fine; ETL pipeline is acceptable
- This is also your hint on whether you need event streaming vs simple queuing — streams are for near-real-time freshness at scale
Consistency (stale vs strong)
Section titled “Consistency (stale vs strong)”- Strong (financial, inventory) → single-leader DB, avoid caches or use write-through cache; may need distributed transactions (2PC or saga)
- Eventual is OK (social feeds, likes) → read replicas, CQRS, cache-first reads are all fine
- Read-your-writes needed → route user’s reads to same replica they wrote to, or use sticky sessions
Ordering (does sequence matter?)
Section titled “Ordering (does sequence matter?)”- Global order needed → use a single ordered log or single partition (e.g. one Kafka partition, single-leader DB); this caps throughput. To scale, relax to per-key or per-entity order and partition by that key—you get strict order where it matters (per user, per conversation) without a global bottleneck
- Per-key/channel order → Kafka partitioned by key solves this cleanly
- No order needed → simple queue (SQS, RabbitMQ), parallel consumers, maximum throughput
Durability (can you lose data?)
Section titled “Durability (can you lose data?)”- Cannot lose → at-least-once delivery with idempotent consumers; WAL-backed DB with replication; Kafka with replication factor ≥ 3
- Exactly-once semantics needed → Kafka transactions, or idempotency keys at application layer
- Can tolerate some loss → in-memory queue or Redis streams with AOF disabled is fine and cheaper
Availability (uptime target)
Section titled “Availability (uptime target)”- 99.9% (8 hrs downtime/year) → active-passive failover is enough
- 99.99%+ → multi-region active-active; no single points of failure anywhere; circuit breakers on all downstream calls
- High availability + consistency together → you’re in CAP theorem territory; usually you pick one or design around it (e.g. DynamoDB global tables with eventual, or CockroachDB for strong)
The Quick Decision Flow
Section titled “The Quick Decision Flow”When you sit down with a new system, scan the checklist and ask:
- High throughput? → Stream or queue
- Low latency reads? → Cache
- Strong consistency? → Single-leader DB, avoid replicas for reads
- Eventual OK? → Replicas, CQRS, denormalize freely
- Can’t lose data? → Durable queue + replicated DB
- Order matters? → Kafka, partitioned by key
- High availability? → Multi-region, circuit breakers
- Long retention + cost? → Tiered storage, columnar DB
The tensions to watch for are the ones that conflict — low latency and strong consistency is the hardest combination, as is high availability and exactly-once delivery. When two requirements pull in opposite directions, that’s where the real design conversation happens.
Related Pages
Section titled “Related Pages”- Staged Design Examples — Stage model (MVP → Growth → Advanced), trigger tables, and how to pick an example.
- System Design Checklist — Building blocks and design choices checklist.
- Optimization Quick Reference — “I have this pain—what do I add?” with full decision matrices.
- Redis vs Kafka: When to Use Which — Concrete decision guide for streams vs queues.